Using generated synthetic data prepares our models to understand the intricacies of every situation, from the most mundane to the rarest of edge cases that drivers will face.
Automatically annotating both real-life and synthetic data sets enables our models to easily curate and augment data sets to ensure robust representation of a variety of contexts within a data set.
Adaptive AI pipeline: Transforming reality into tailored solutions
Our integrated AI pipeline transforms complex real-world scenarios into intelligent, adaptive solutions. We leverage generative AI and precision simulation for comprehensive data synthesis, combined with multimodal AI for automated annotation and optimized data selection, resulting in lightweight, customer tailored models.
Modeling the complexity and dynamism of real life with generative AI
Synthetic Images & Automatic Annotation

Simulation
Our in-house simulation generates synthetic video footage to complement real-world data. This allows us to reproduce rare driving scenarios and edge cases critical for comprehensive analysis. The result: more robust models capable of identifying unusual road conditions, traffic patterns, and safety hazards underrepresented in field data.
Building customer-tailored lightweight solutions using multimodal AI
Data Composition Analysis
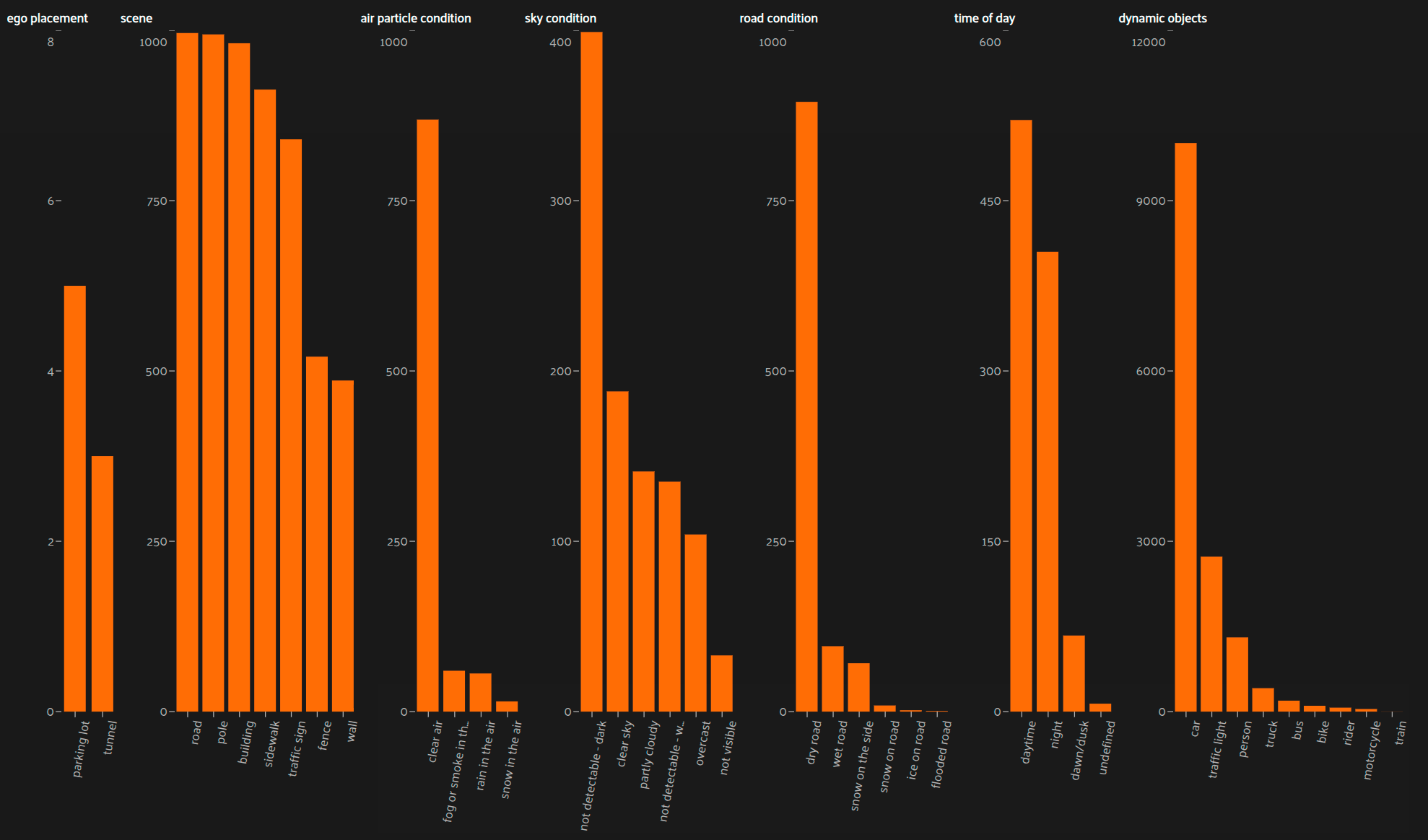
From big data to precision models: identifying the right data for specific customer needs is key to optimizing both training resources and model performance. Our Data Composition Analysis extracts human-understandable context from datasets, enabling smarter data selection and more targeted model development.
Multimodal Vision-Language Model
.png)
Automating the labor-intensive annotation process is crucial for scaling AI development efficiently. Our Multimodal Vision-Language Model autonomously annotates diverse visual data, dramatically reducing manual labeling requirements while maintaining high-quality standards for training dataset creation.
